
RC21. Celebrating Minor Triumphs
Daily dispatches from my 12 weeks at the Recurse Center in Summer 2023
Dear journal,
I’ve had a number of excellent days in my 4+ weeks at RC so far – productive, social, brimming with learnings and challenges and insights. In fact I’d venture to say most of my RC days have been this way. But today felt like a special triumph where I experienced minor successive breakthroughs on several different projects all in the same day, and, well, I suppose I feel compelled to commit said triumphs to blog, if for no other reason than to reminder my future self of what a good day feels like.
DateTime Feature Extraction for ML Model
Lately I’ve been committing more time to an ML project that is RC-adjacent. After spending a while with the dataset (which shall remain anonymous for various reasons) for the past few weeks and doing all the usual parsing and wrangling and EDA, I decided it was time to start modeling it using XGBoost.
I took an incremental approach and added one feature or group of related features at a time, since I was curious to see how each addition changed the model’s accurace. Most of this process involved one-hot encoding categorical features and tokenizing a few text features – the low-hanging fruit of this particular project. After doing the easy stuff, my model’s RMSE was within about 2 standar deviations of the target variable mean.
But I have a variety of DateTime features, as well. So what I focused on today was extracting some new features from these DateTime features that encode a variety of very useful signal when it comes to cyclicality and seasonality.
Here are a few anonymized charts that demonstrate what I mean.
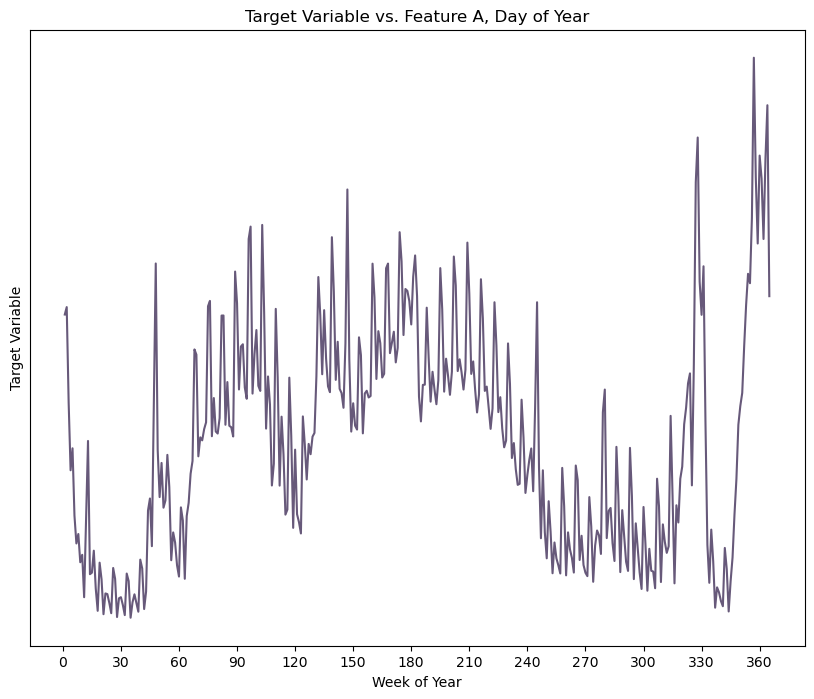
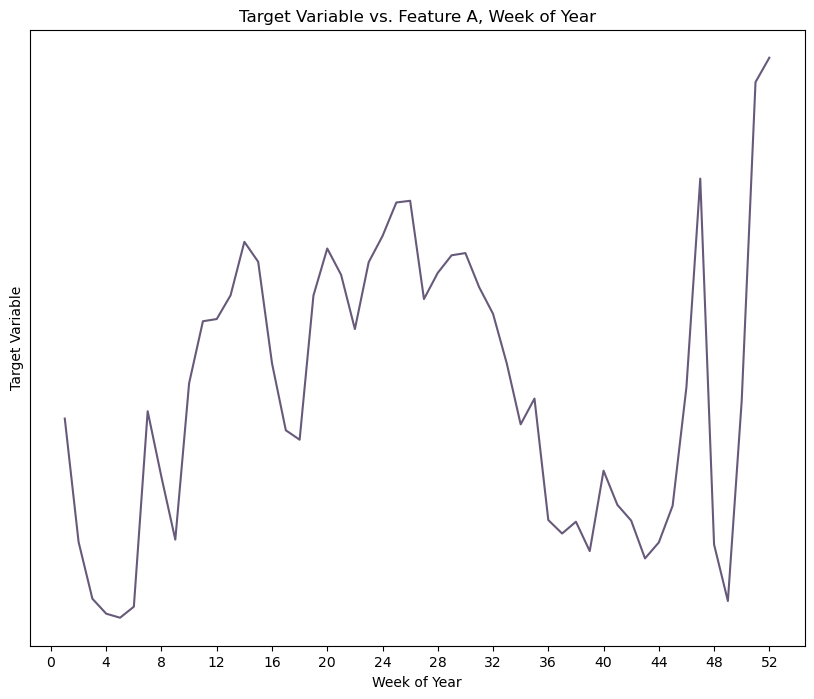
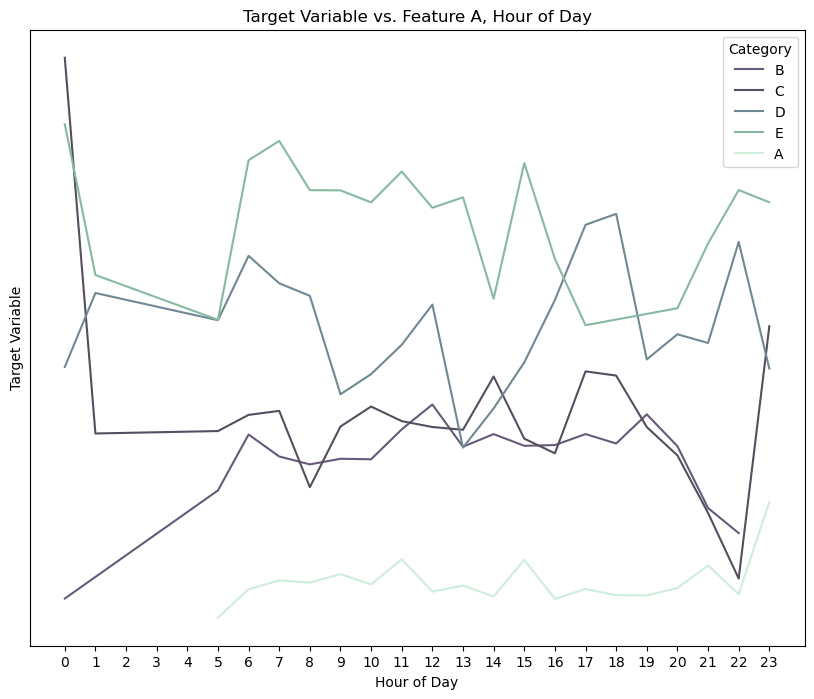
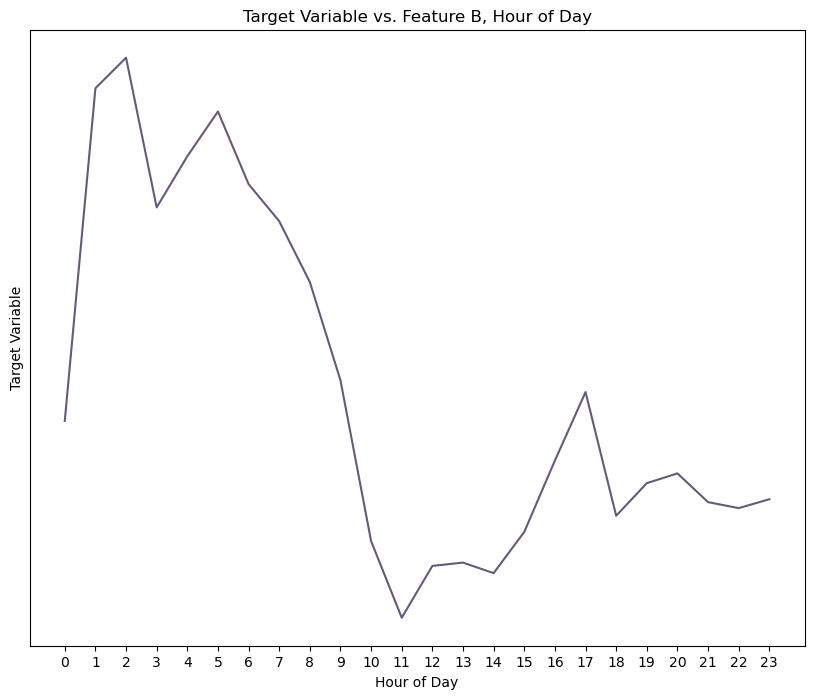
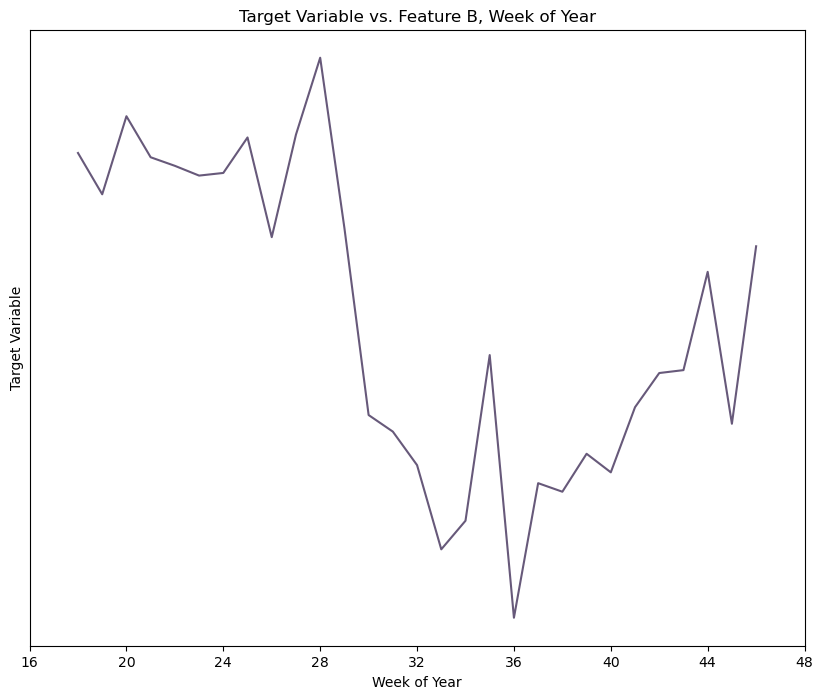
Because I have these very rich DateTime features, I’m able to group the data by various periods – day, week, or hour of day – to discover clear seasonal and cyclical trends. So these new periods went into my model and out the other end came an RMSE that was falling within one standard deviation of my target variable mean, which feels pretty damn good for a morning’s work.
Assembly Language, Part I
After this success, I turned my attention to nand2tetris. This week we’re writing assembly, which is tricky for a number of reasons that I hope to get into in a later blog post. For now I’ll say that it involves manually selecting 16-bit values stored in memory at 16-bit addresses, writing that information temporarily to one of two registers, and operating on the information contained in the registers using the ALU I designed week or two ago, and then perhaps storing the result somewhere back in memory.
The first exercise, which I paired on yesterday with some groupmates, was to create an algorithm to multiply two numbers stored at two RAM addresses. If the first value is x and the second value is y, this is a matter of adding x to itself y times. But doing this in assembly language meant figuring out how to access those values, create and store a counter in memory, increment it, and keep on looping until the counter state, in tandem with the y value, create a jump condition.
Today’s challenge was a substantial leap in difficulty. The problem was to incrementally blacken pixels of a screen when a key is pressed and to blank them out incrementally when a key is released. The screen comprises of 256 rows of 512 pixels per row, and each row is represented by 32 consecutive 16-bit words. If the screen’s memory address starts at 0, in other words, addresses 0 through 31 comprise the first row of pixels, 32 through 61 the second row, etc. etc. To darken the top left pixel, then, the 16-bit word at address 0 would be set to 1, which is 0000000000000001 in binary. To darken the first two pixels of the screen, the value at address 0 would be 3, or 0000000000000011 in binary. And on and on.
In this particulay work session, I decided that darkening or lightening the screen pixel by pixel was a bit too complex, so I focused on going word by word. So the process looked like this:
- set an interator variable to the first memory location of the screen
- if a key is pressed, negate the 16-bit word at
i, otherwise set it to 0 - increment
iso that on the next loop we repeat the above process with the next 16-bit word - if
iever exceeds the screen’s memory block, then reset it back to first screen location
In pseudocode:
i = 16384 // 16384 is the where screen addresses begin
while True: // infinite loop
if keydown:
screen[i] = -1 // '1111111111111111' in binary
else if keyup:
screen[i] = 0 // '0000000000000000' in binary
i++ // increment `i` so we move on to next screen address
if i >= 24576: // if `i` exceeds the screen's address space, reset it to first address
i = 16384
It’s a bit more complicated in assembly, but that’s the gist of it.
In any case, I got this far and succeeded in darkening or lightening the screen 16 pixels at a time. What I really wanted to do, though, was find a way to go pixel by pixel. That would have to wait until the afternoon.
Linked List Problem
I went from staring at assembly language to working through a linked list problem from CTCI with another recurser. This one was fun and also a subject I plan to explore in greater depth at a future time.
The problem was to partition a linked list based on a pivot value. For instance, given the list
5 -> 2 -> 9 -> 4 -> 6
and pivot value x = 5, we want to transform the linked list in place such that all the nodes with values less than 5 are on the left side of the linked list, and all the nodes with values greater than or equal to 5 are on the right side of the list, like so:
2-> 4 -> 9 -> 5 -> 6
The order itself doesn’t matter so long as the linked list is partitioned correctly.
Our approach was to use left and right pointers to look for nodes that needed swapping: the left pointer would stop before a node that was >= x, and the right pointer would traverse forward until reaching a node that was < x. At that point, we do a switcheroo, which is a bit complicated with a linked list, since we need to sever and reattach two nodes (and each of their two connections) simultaneously.
Coffee Chat
From linked lists I jumped into a wonderful coffee chat with someone who is a frequent pairing partner but whom I hadn’t really met with yet. Turns out she’s an accomplished artist with much in common.
The energizing chat was an occasion to reflect a bit more on RC coffee chat culture, which recently I’ve begun to prioritize. This is interesting to me, since when working on my diss. I used to have a very hard time indeed justifying taking 30 minutes away from writing to chat about life and work with colleagues. It’s true that such meetings were an opportunity to talk through and generate ideas, get feedback, harvest some inspiration and motivation to carry me through the next stretch. But ultimately writing was for me such an agonizing and arduous form of work, and one that was so painfully, painfully slow, that the trade-off rarely struck me as worth it. Especially since ultimately I would have to work through the ideas in isolation anyway.
In this context, however, I’m finding that my relationship to casual chats transformed, since the very activity that in another time I would have viewed as taking away from my work is now contributing to it and enabling it. A chat like the one I had today turns out always to be the right move, not only because it was fun and restorative and energizing but also because it is a net contributor. These conversations have a way of exposing me to new ideas, new aspects of enginerering, new methodologies, new attitudes and approaches to problems, new stories about folks’ often unlikely trajectories into technology. They’re expansive is what they are. Which is not to say that academia’s equivalents were not, but perhaps only that they often did not overcome the more abiding sense of scarcity, which is largely the feeling that deep research and writing left me with.
Assembly Language, Part II
In the afternoon, I reconvened with some nand2tetris folks, but only long enough to ensure that I was on the right path. Once I got that reassurance, I was eager to go solo again and see if I could improve my current screen-darkening and -lightening program so that it went pixel-by-pixel rather than word-by-word.
It took some work, but eventually I cracked it.
(RESET) // Jump here every time I need to reinitialize `i`
@SCREEN
D=A
@i
M=D // initialize `i` to first screen address
(MAINLOOP)
@bitsplace // variable to increment from 1, 2, 4, 8, 16, 32, 1 ...
M=1 // set bitsplace=1
@j // variable to increment through 16-bits of word
M=0 // set j=0
(WORDLOOP)
@KBD // get keyboard status and jump
D=M
@ISKEYUP
D;JEQ
@ISKEYDOWN
D;JGT
(ISKEYUP) // if key is up
@bitsplace
D=!M // negate `bitsplace`...
@i
A=M
M=M&D // ... and AND it with current value @i
@ENDIF
0;JMP
(ISKEYDOWN) // if key is pressed
@bitsplace
D=M
@i
A=M
M=M|D // OR `bitsplace` with current value @i
@ENDIF
0;JMP
(ENDIF)
@bitsplace
D=M
@bitsplace // double `bitsplace
MD=D+M
@j
MD=M+1 // increment `j`
@16
D=D-A // D = `j` - 16
@WORDLOOP
D;JLT // while `j` - 16 < 0, keep looping through word at @i
@i
MD=M+1 // increment `i` for subsequent screen address
@24575 // if i - 24575 > 0, then we've exceeded screen addresses;
D=D-A
@RESET
D;JGT
@MAINLOOP
0;JMP // infinite loop
What I needed to modify the screen pixel by pixel was a way of incrementing the value of each word such that, if a key was pressed, the value at memory address i would proceed as follows:
0000000000000001
0000000000000011
0000000000000111
...
0011111111111111
0111111111111111
1111111111111111
My idea was to have a value in memory that targets each consecutive place of this 16-bit value, like this, where j is a counter from 0 to 16, and bitsplace is a value that curresponds to the bits place that we want to update on the current loop iteration:
| j | bitsplace | integer equivalent |
|---|---|---|
| 0 | 0000000000000001 | 1 |
| 1 | 0000000000000010 | 2 |
| 2 | 0000000000000100 | 4 |
| 3 | 0000000000001000 | 8 |
| 4 | 0000000000010000 | 16 |
| 5 | 0000000000100000 | 32 |
| 6 | 0000000001000000 | 64 |
| 7 | 0000000010000000 | 128 |
| 8 | 0000000100000000 | 256 |
| 9 | 0000001000000000 | 512 |
| 10 | 0000010000000000 | 1024 |
| 11 | 0000100000000000 | 2048 |
| 12 | 0001000000000000 | 4096 |
| 13 | 0010000000000000 | 8192 |
| 14 | 0100000000000000 | 16384 |
| 15 | 1000000000000000 | 32768 |
Once we have that bitsplace integer, we can:
ORit to the current screen word value @i when KEYDOWNANDits negation with the current screen word value @i when KEYUP
Here j is ensuring that we count from 0 to 16 for each successive word, and bitsplace is doubling each time in order to target the next most significant bit. There’s probably a way to use only the bitsplace variable and exit the loop when bitsplace > 65536 instead of when j > 15. The problem is that the next time bitsplace doubles, it becomes a 17-bit number and thus overflows the 16-bit space in memory, so I think accomplishing this would entail having a break condition at the end of WORDLOOP as soon as bitsplace = 65536.

LeetCode Pairing
At night I worked through a matrix rotation problem on LeetCode.
Say we have the following matrix:
[[4, 9, 2],
[1, 3, 0],
[5, 6, 8]]
We want to rotate it 90 degrees clockwise so we end up with:
[[5, 1, 4],
[6, 3, 9],
[8, 0, 2]]
The first insight I had was that it might be easiest to tackle this in two steps:
- transpose the matrix (reflect it over it’s main axis)
- reverse each row
// Original Matrix
[[4, 9, 2],
[1, 3, 0],
[5, 6, 8]]
// Step 1: transpose
[[4, 1, 5],
[9, 3, 6],
[2, 0, 8]]
// Step 2: reverse each row
[[5, 1, 4],
[6, 3, 9],
[8, 0, 2]]
At first I thought this would be a simple matter of creating a nested loop: we loop through each row and then each column, swapping the item at matrix[row][col] with the item at matrix[col][row], and vice versa. But there’s a problem, since we end up double swapping everything, and then ending up with the matrix with which we began.
For instance, when row=0 and col=1, we are going to swap 1 and 9 – great! We do that, and then carry on. But then when row=1 and col=0, as it inevitably will, we re-swap 9 (the item now at matrix[1][0]) with 1 (the item now at matrix[0][1]), thus undoing our previous hard work.
This was really a head scratcher for a while, until all of a sudden I realized that avoiding touching the already-swapped items a second time was a matter of looping through the coloums not from 0 each time but from wherever row is. That way, on our first iteration through the outer row loop, we touch and swap all of the cells marked A below, the second time through we touch and swap the B cells, the third time the C ones, and lastly the D cell (which isn’t necessary actually since nothing needs to happen on the final loop for creating the transpose).
[[A A A A]
[A B B B]
[A B C C]
[A B C D]]
Here’s the code we ended up with (which evidently can be optimized, at least a little, based on the above observation):
def rotate(matrix):
'''
Rotate matrix 90 degrees clockwise in place.
'''
# Step 1: Transpose matrix, O(N)
for i in range(len(matrix)):
for j in range(i, len(matrix[0])):
matrix[i][j], matrix[j][i] = matrix[j][i], matrix[i][j]
# Step 2: Reverse each row, O(N)
for row in matrix:
row.reverse()
These medium LeetCode problems often stump me, so savoring the victory.
SICP
The last activity of my day (night, by now) was to work on some SICP. The accomplishments here are less concrete, since I’m just going through exercises in Chapter 2, but I’m finding my stride and feel Lisp coming to me more easily now that we’ve moved on from math-related algorithms to data structures.